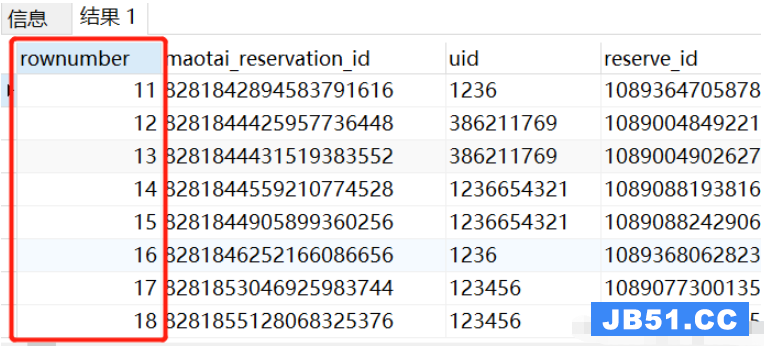
我有一个文件,其中的条目是条目被建模为代数数据类型,看起来像
Word { _frq=1,_fra="le",_eng="the; him,her,it,them",_deu="der,die,das; er,sie,es",_uses=[Determiner [],Pronoun []],_phrase=" vive la politique,vive l'amour",_sentence="long live politics,long live love",_satz="Lang lebe die Politik,lang lebe die Liebe."
}
大多数情况下,德语翻译_deu =和_satz =通常只是一个空字符串,我想在程序中更新.
现在我有几个问题:
1.是否有一个使用Haskell数据类型的数据库用于haskell(我真的很想在我的数据库中输入类型)?
我找到的东西是HDBC绑定到MySQL等,以及其他一些xml / JSON的东西.
>如果我更新文件而不是使用数据库,有没有办法重新编译整个程序 – 这样做会有点乏味.
和第三个问题
我想将学习的词汇保存在需要经常更新的数据结构中,因为在每个学习步骤中我更新一个表示该词知识的数字 – 并在插入/或之后对该数据结构进行排序.然后我根据它在这个数据结构中的位置选择一个新单词.对于进行完整列表遍历而言,列表似乎效率低下,如果有更好的解决方案,排序是一项很大的工作.
最后一点说明我只有5000个列表条目,所以也许它担心速度在错误的地方?
解决方法
在维护模型中的类型安全性方面,它可以满足您的要求.我不确定这对你有多大帮助,但我已经把它用在了几个网络应用程序中,包括here和here(第二个是基准测试尝试使HDBC对抗MongoDB和AcidState,因此您可以使用它来查看三者如何在Haskell Web应用程序的上下文中实现比较.
对于你的第三个问题,在5000次插入/读取时,你真的不应该担心性能.如果你看一下those benchmarks I mentioned,那么“大”基准测试会在很短的时间内完成(相对较小的)5万笔交易,并且它们比你似乎做的更加插入.
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。