

正则表达式
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class regexp_01 {
public static void main(String[] args) {
String s = "由于在开发Oak语言时,尚且不存在运行字节码的硬件平台,所以为了在开发时可以对这种语言进行实验研究,他们就在已有的" +
"硬件和软件平台基础上,按照自己所指定的规范,用软件建设了一个运行平台,整个系统除了比C++更加简单之外,没有什么大的区" +
"别。1992年的夏天,当Oak语言开发成功后,研究者们向硬件生产商进行演示了Green操作系统、Oak的程序设计语言、类库和其" +
"硬件,以说服他们使用Oak语言生产硬件芯片,但是,硬件生产商并未对此产生极大的热情。因为他们认为,在所有人对Oak语言" +
"还一无所知的情况下,就生产硬件产品的风险实在太大了,所以Oak语言也就因为缺乏硬件的支持而无法进入市场,从而被搁置了下" +
"来。\n" +
"1994年6、7月间,在经历了一场历时三天的讨论之后,团队决定再一次改变了努力的目标,这次他们决定将该技术应用于" +
"万维网。他们认为随着Mosaic浏览器的到来,因特网正在向同样的高度互动的远景演变,而这一远景正是他们在有线电视网中看" +
"到的。作为原型,帕特里克·诺顿写了一个小型万维网浏览器WebRunner。";
//1.\\d表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";
//2.创建模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:创建匹配器matcher,按照正则表达式的规则
Matcher matcher = pattern.matcher(s);
//4.开始匹配
//matcher.find() 完成的任务
//1.根据指定的规则,定位满足规则的子字符串(1998)
//2.找到后,将子字符串的开始索引记录到matcher对象的属性int[] groups的groups[0]中,
// 把子字符串的结束的索引+1的值记录到groups[1]
//3.同时记录oldLast的值为groups[1],即下次执行find时,从oldLast开始匹配
//什么是分组,比如(\\d\\d)(\\d\\d),正则表达式中有() 表示分组,第一个()表示第一组,第二个()表示第二组,以此类推
//例如找到(19)(98)
//则记录第一组()匹配到的字符 groups[2]=0 (第一组中1所在的下标) groups[3]=1+1=2 (第一组中9所在的下标加1)
//则记录第二组()匹配到的字符 groups[4]=2 (第二组中9所在的下标) groups[5]=3+1=4 (第二组中8所在的下标加1)
//调用时,matcher.group(1)和matcher.group(2)返回第一组和第二组截取的字符串
//matcher.group(0)完成的任务
//根据groups[0]和groups[1]记录的位置,截取子字符串,即[groups[0],groups[1])
//如果正则表达式取出的组大于定义的组,则由于初始化groups为-1,会出现数组越界,建议查看源码
while(matcher.find()){
System.out.println("找到:"+matcher.group(0));
System.out.println("找到第一组内容:"+matcher.group(1));
System.out.println("找到第二组内容:"+matcher.group(2));
}
}
}
一.底层原理
(1).matcher.find() 完成的任务
1.根据指定的规则,定位满足规则的子字符串
2.找到后,将子字符串的开始索引记录到matcher对象的属性int[] groups的groups[0]中,
把子字符串的结束的索引+1的值记录到groups[1]
3.同时记录oldLast的值为groups[1],即下次执行find时,从oldLast开始匹配
(2)matcher.group(0)完成的任务
根据groups[0]和groups[1]记录的位置,截取子字符串,即[groups[0],groups[1])
(3)什么是分组,比如(\d\d)(\d\d),正则表达式中有() 表示分组,第一个()表示第一组,第二个()表示第二组,以此类推
例如找到(19)(98)
则记录第一组()匹配到的字符 groups[2]=0 (第一组中1所在的下标) groups[3]=1+1=2 (第一组中9所在的下标加1)
则记录第二组()匹配到的字符 groups[4]=2 (第二组中9所在的下标) groups[5]=3+1=4 (第二组中8所在的下标加1)
调用时,matcher.group(1)和matcher.group(2)返回第一组和第二组截取的字符串
即:matcher.group(0)表示匹配到的字符串,matcher.group(1)表示匹配到的第一组子字符串,matcher.group(2)表示匹配到的第二组子字符串…依此类推
二.正则表达式语法
(1)转义号\\
在检索特殊字符( .*+()$/?[]^{} )时,需要用到\\,否则报错
在java中,两个\\代表其他语言中一个\
(2)字符匹配符


\\w还可以匹配下划线
如何不指定大小写?


\\s匹配任何空白字符
\\S匹配任何非空白字符
(3)选择匹配符

(4)限定符
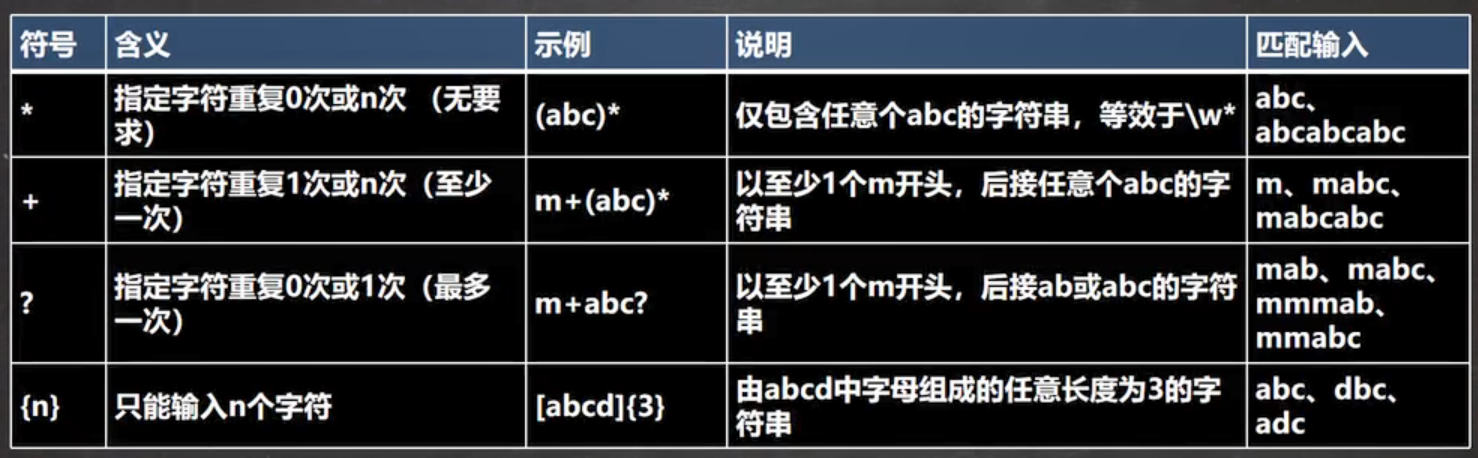

Java匹配是贪婪匹配,即尽可能匹配多的
非贪婪匹配,在限定符后面加一个 ?
(5)定位符

\\b边界可能是字符串最后,也可以是空格的字符串子串的后面
(6)分组

演示代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class regexp_04 {
public static void main(String[] args) {
//非命名捕获
// String content = "zhrzhr s7789 nn1189n";
// String regStr = "(\\d\\d)(\\d\\d)";
//
// Pattern pattern = Pattern.compile(regStr);
// Matcher matcher = pattern.matcher(content);
//
// while(matcher.find()){
// System.out.println(matcher.group(0));
// System.out.println("第一个分组为:"+matcher.group(1));
// System.out.println("第二个分组为:"+matcher.group(2));
// }
//命名捕获
String content = "zhrzhr s7789 nn1189n";
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println(matcher.group(0));
//可以用非命名捕获的内容,也可以通过名字来获取
System.out.println("第一个分组为:"+matcher.group("g1"));
System.out.println("第二个分组为:"+matcher.group("g2"));
}
}
}
非捕获分组

举例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class regexp_05 {
public static void main(String[] args) {
//找吃火锅 吃麻辣烫 吃烧烤中的子串 (?:... )
String content = "吃火锅 吃麻辣烫 吃烧烤";
String regStr = "吃(?:火锅|麻辣烫|烧烤)";
// Pattern pattern = Pattern.compile(regStr);
// Matcher matcher = pattern.matcher(content);
//
// while(matcher.find()){
// System.out.println(matcher.group(0));
// }
//找吃火锅 吃麻辣烫中的吃 (?= ...)
// regStr = "吃(?=火锅|麻辣烫)";
// Pattern pattern = Pattern.compile(regStr);
// Matcher matcher = pattern.matcher(content);
//
// while(matcher.find()){
// System.out.println(matcher.group(0));
// }
//找吃这个关键字,但是找不是吃火锅中的吃 (?!... )
regStr = "吃(?!火锅)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println(matcher.group(0));
}
}
}
三.正则表达式常用类

1.Pattern.matcher(regStr,content)是整体验证,常用方法,返回Boolean值
2.Pattern常用方法

注意:end()是最后元素的下标加1
3.Matcher常用方法
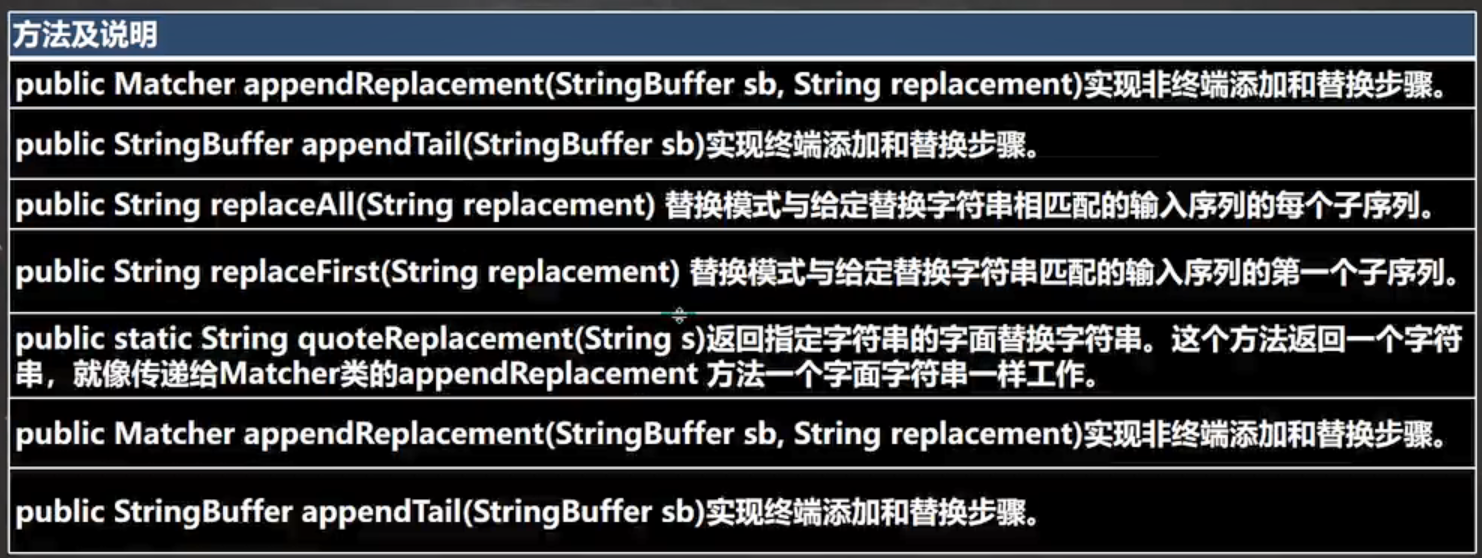
注意:replaceAll("…")返回的才是替换后的字符串,原字符串不变
四.反向引用

举例
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class regexp_09 {
public static void main(String[] args) {
//判断是否是4位回文数字
// String content = "1221";
// String regStr = "(\\d)(\\d)\\2\\1";
//
// Pattern pattern = Pattern.compile(regStr);
// Matcher matcher = pattern.matcher(content);
//
// if(matcher.find()){
// System.out.println(matcher.group(0));
// }
String content = "12321-333999111";
String regStr = "\\d{5}-(\\d)\\1\\1(\\d)\\2\\2(\\d)\\3\\3";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if(matcher.find()){
System.out.println(matcher.group(0));
}
}
}
将 我…我要…学学学习习Java 变为 我要学习Java
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class exercise_03 {
public static void main(String[] args) {
String str = "我...我要...学学学习习Java";
//先去除.
str = Pattern.compile("\\.").matcher(str).replaceAll("");
//再去除重复的字
str = Pattern.compile("(.)\\1+").matcher(str).replaceAll("$1");
System.out.println(str);
}
}
验证电子邮件是否合法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author ZHR
* @version 1.0
**/
public class exercise_04 {
public static void main(String[] args) {
//验证电子邮件是否合法
String content = "[email protected]";
String regStr = "^\\w+@([a-zA-Z]+\\.)+[a-zA-Z]+$";
//这里使用String的match方法,整体匹配正则表达式
if(content.matches(regStr)){
System.out.println("匹配成功");
}else{
System.out.println("匹配失败");
}
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。