windows环境配置:
步骤:
- 安装python
官网下载
http://www.seleniumhq.org/
https://www.python.org/downloads/windows/
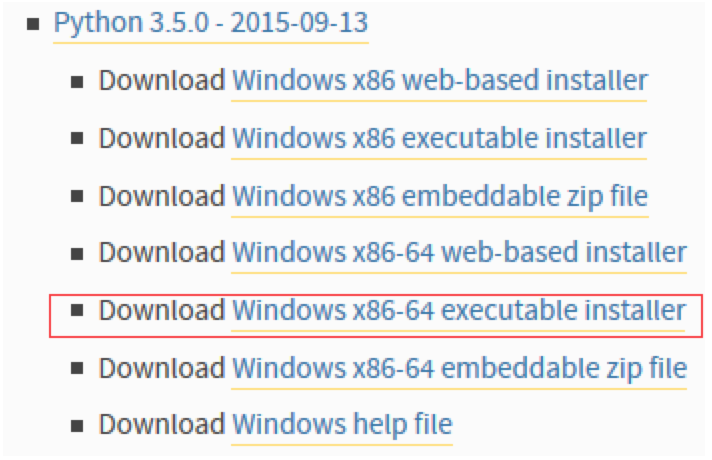
3.5安装包在安装时会有一个环境变量的配置勾选,一定要勾选上不然就要单独去配置环境
- 安装selenium
在官网
http://www.seleniumhq.org/download/选择python下载
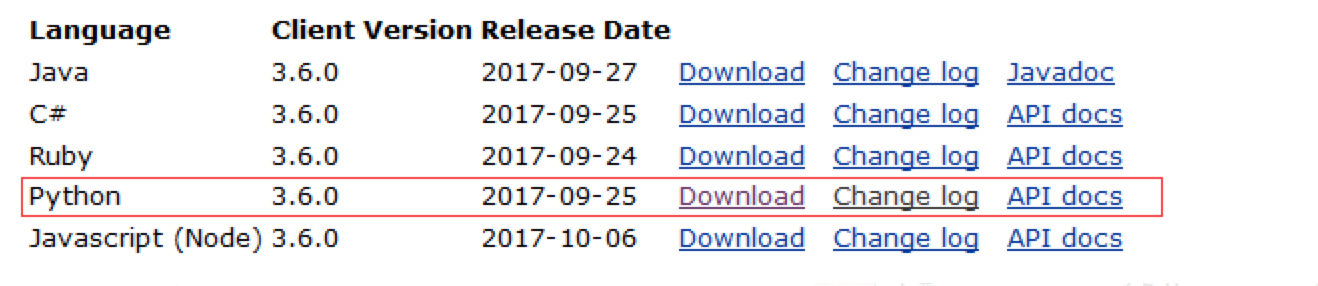
进入python对selenium的资源库网站:
https://pypi.python.org/pypi/selenium
下载后要安装selenium还需要先安装pip
https://pip.pypa.io/en/latest/installing/
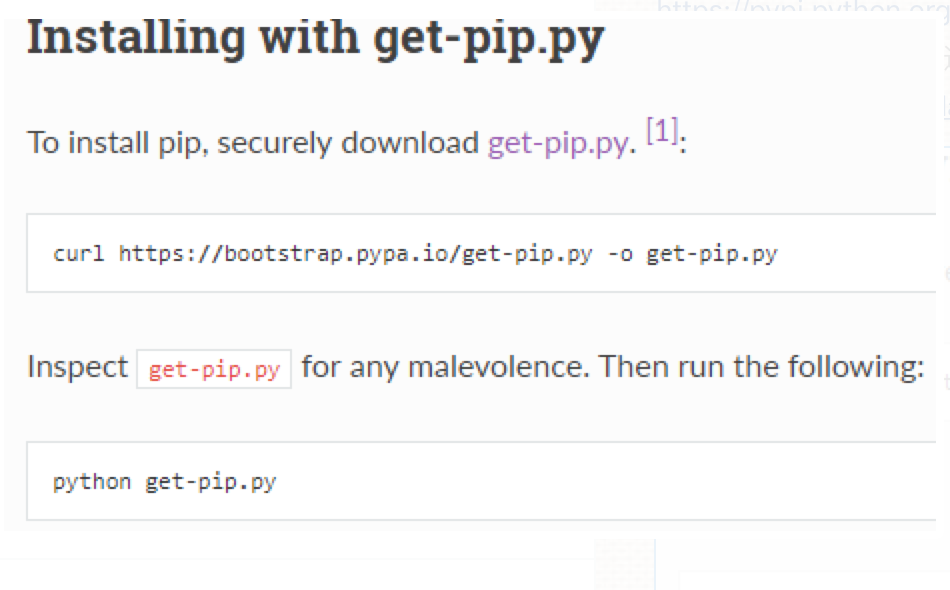
打开get-pip,将其右键另存为get-pip.py
get-pip的安装方法:
使用方法:在window中打开CMD,直接运行:python get-pip.py
直接输入pip -V,进行验证
pip 9.0.1
selenium-3.6.0的安装方法:
在pip安装好后,在cmd中进入selenium-3.6.0文件夹中,直接运行如下
C:\Users\Administrator\Desktop\selenium-3.6.0>python setup.py install
输入pip show selenium,进行验证
Name: selenium
Version: 3.6.0
Summary: Python bindings for Selenium
- 驱动下载
http://docs.seleniumhq.org/download/

例如:firefox的版本是42以上,必须要使用第三方驱动geckodriver-v0.16.1-win64
下载地址:
https://github.com/mozilla/geckodriver/releases
或:
https://sites.google.com/a/chromium.org/chromedriver/downloads
最好是在FQ下载
将geckodriver放到Python根目录下
- 运行
在Mac中安装chromeDriver
驱动地址,chrome的版本号要对应驱动版本号,我当下是chrome66—driver2.38
http://chromedriver.storage.googleapis.com/index.html?path=2.38/
然后将解压后的文件放到/usr/local/bin目录下
重新运行python代码
P35
不同编程语言下使用WebDriver,抛去语法差异,在不同语言中实现百度搜索自动化实例主要有以下几个步骤:
- 首先导入Selenium(webdriver)相关模块
- 调用Selenium的浏览器驱动,获取浏览器语句并启动浏览器(不同浏览器要安装不同驱动)
driver = webdriver.Firefox()
driver = webdriver.Ie()
driver = webdriver.Chrome()
driver = webdriver.Safari()
- 访问百度地址
- 操作页面元素
- 关闭浏览器
如Python编写,案例:
''''''''''''''''''''''''
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
# driver = webdriver.Firefox()
driver = webdriver.Ie()
driver = webdriver.Chrome()
driver = webdriver.Safari()
driver.get("http://www.baidu.com")
sleep(2)
driver.find_element_by_id("kw").send_keys("猫星人")
driver.find_element_by_id("su").click()
sleep(10)
driver.quit()
''''''''''''''''''''''''''''
保存为baidu.py
在cmd中运行:python baidu.py
安装python时遇到的问题:
当安装python后,启动时报错
总是提示文件api-ms-win-crt-process-l1-1-0_jb51或api-ms-win-crt-runtime-l1-1-0缺失
说明你的window系统可能没有进行过升级
这时就需要安装vc2015_x64_14.0.24215这个文件,相当于打补丁吧
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。

