

此博文是第十五周的博客作业,内容是介绍软件测试工具,并介绍如何在自己的项目中具体使用。
一、 单元测试工具
- Junit测试工具
(1) 介绍
JUnit是一个开放源代码的Java测试框架,用在编写和运行可重复的测试脚本之上。它是单元测试框架体系xUnit的一个实例。JUnit框架功能强大,目前已成为Java单元测试的事实标准,如果与Mock对象、HttpUnit、DBUnit等配合使用,基本上能满足日常的测试要求。
(2) 特性
A) 可以使测试代码与产品分开,这更有利于代码的打包发布和测试代码的管理。
B) 针对某一个类的测试代码,以较少的改动便可以应用另一个类的测试,JUnit 提供了一个编写测试类的框架,使测试代码的编写更加方便。
C) 易于集成到程序中的构建过程中,JUnit和Ant 的结合还可以实施增量开发。
D) JUnit 的源代码是公开的,故而可以进行二次开发。
E) JUnit 具有很强的扩展性,可以方便地对JUnit 进行扩展。
(3) 使用
该测试工具可以从http://www.junit.org/下载,并作为一个Java的扩展库在eclipse中安装。
第一步,编写需要测试的代码。
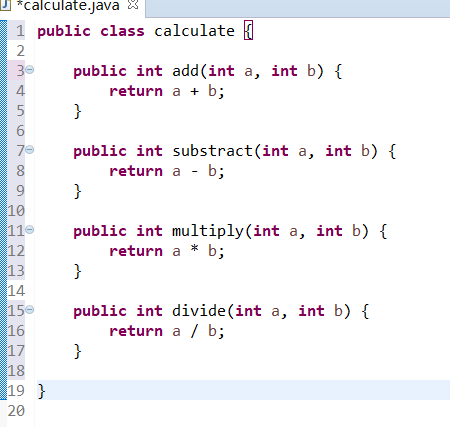
第二步
导入JUnit
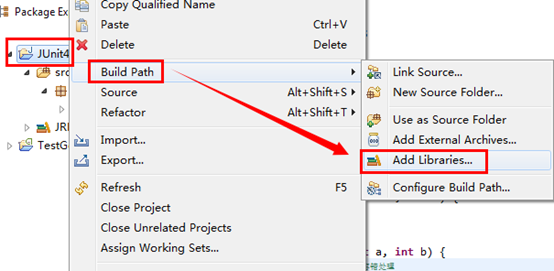
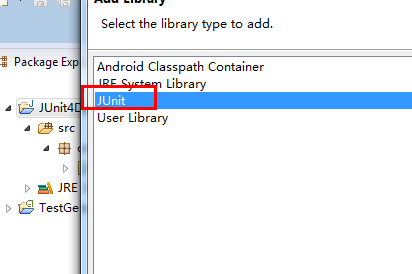
第三步,编写测试的代码
import static org.junit.Assert.*;
import org.junit.Test;
public class calculatetest {
@Test
public void add() {
assertEquals(8,new calculate().add(3, 5));
}
}
用来测试calculate类中的add()方法
第四步,运行测试代码
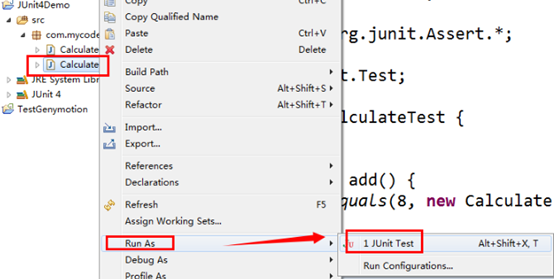
最后,对结果进行分析
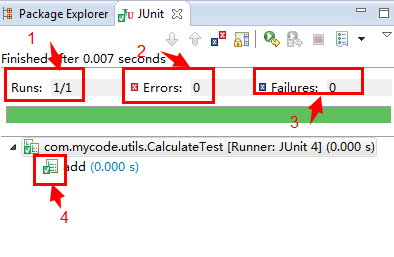
(1). Runs:表示总共有几个测试方法,已经运行了几个;
(2). Errors:表示抛出异常的测试方法的个数;
(3). Failures:表示失败的测试方法的个数;
(4). 打钩:表示通过测试方法。
(5). 另外有个绿色的进度条表示测试成功,红色的进度条则表示测试失败。
二、功能测试工具
- Selenium IDE
(1)介绍
Selenium IDE(集成开发环境),Firefox的插件,可以录制、回放并编辑测试脚本,是Selenium脚本的开发平台。
(2)特性
A)适合Web应用的测试,可直接运行在浏览器之上,所见即所得,因为Selenium的核心是用于JavaScript编写的。
B)跨平台,支持多操作系统和各种浏览器。
C)支持分布式应用的测试,构造一个完整的解决方案。
D)支持两种开发脚本的模式Test Runner 和Driven,使测试既可以完全在浏览器内运行,也可以脱离浏览器在远程机器上运行。
E)支持多种脚本语言,包括Java、C#、PHP、Perl、Python和Ruby等。
(3)介绍
首先,打开火狐浏览器(其他浏览器也可以),然后右上角的测试工具。
紧接着创建一个新的工程(当然如果你有现成的就可以直接打开)
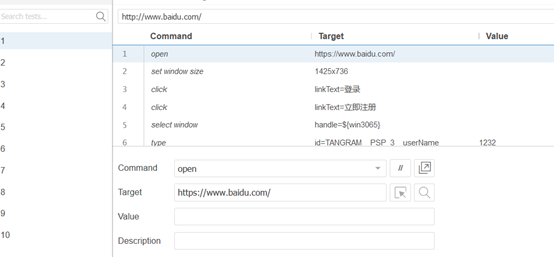
创建完工程之后,便对工程取名,然后就是输入你想要测试的网址,我是对百度进行了测试。

接下来就是最关键的一步,便是写好测试用例并且依次进行测试。(下面是我的测试用例和结果)

三、性能测试工具
- JMeter测试工具
(1) 介绍
JMeter 是开源的性能测试工具的代表,最早是为了完成Tomcat的前身Jserv的性能测试而诞生的。随着J2EE应用的不断发展,其功能不再局限于Web服务器的性能测试,还涵盖了数据库、FTP、LDAP服务器等各种性能测试,以及可以和JUnit、Ant等工具的集成应用。它可以针对服务器、网络或其他被测试对象等模拟大量并发负载来进行强度测试,并分析不同压力负载下的系统整体性能,包括性能的图形分析、产生相应的统计报表,包括各个URL请求的数量、平均响应时间、最小/大响应时间、错误率等。
(2) 使用
从官方网站:http://jmeter.apache.org/下载,解压后,运行 “bin/jmeter.bat”。(在运行之前需要配置,和装Java时的配置差不多,这里不作详细说明)
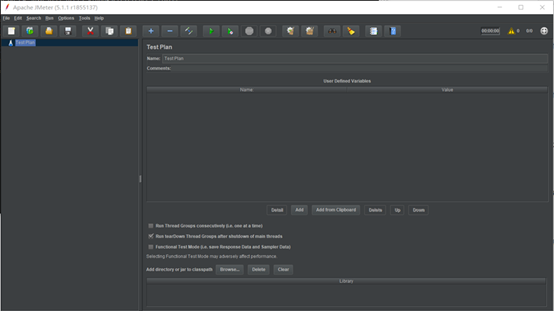
添加进程组
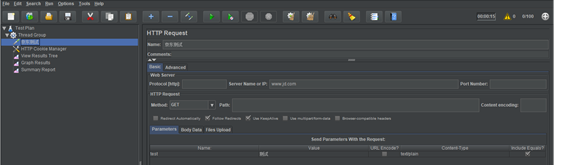
创建Http请求,设置名称、请求方法路径和请求参数
添加察看结果树,右键点击线程组,在弹的菜单(添加--->监听器--->察看结果树)中选择察看结果树。
添加聚合报告,右键点击线程组,在弹的菜单(添加--->监听器--->聚合报告)中选择聚合报告。
添加图形结果,右键点击线程组,在弹的菜单(添加--->监听器--->图形结果)中选择图形结果。
四、总结
本次介绍的软件测试工具为Junit、JMeter和Selenium IDE,我觉得三者中最简单的是Selenium IDE,虽然仅仅测试于网站,但是测试结果很清晰了然。而最难学的就是JMeter , JMeter的一个很大的亮点在于,它能够通过让我们用断言创造测试脚本来验证我们的应用程序是否返回了我们期望的结果,从而帮助我们回归测试我们的程序。但是学习起来还是有一定难度的。由于参考资料比较有限,所以相对于Selenium IDE而言还是后者相对容易。由于我们项目还需进一步完成,所以无法进行测试。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。