

这是房源的地址:
......
检查元素:
网页第一部分:
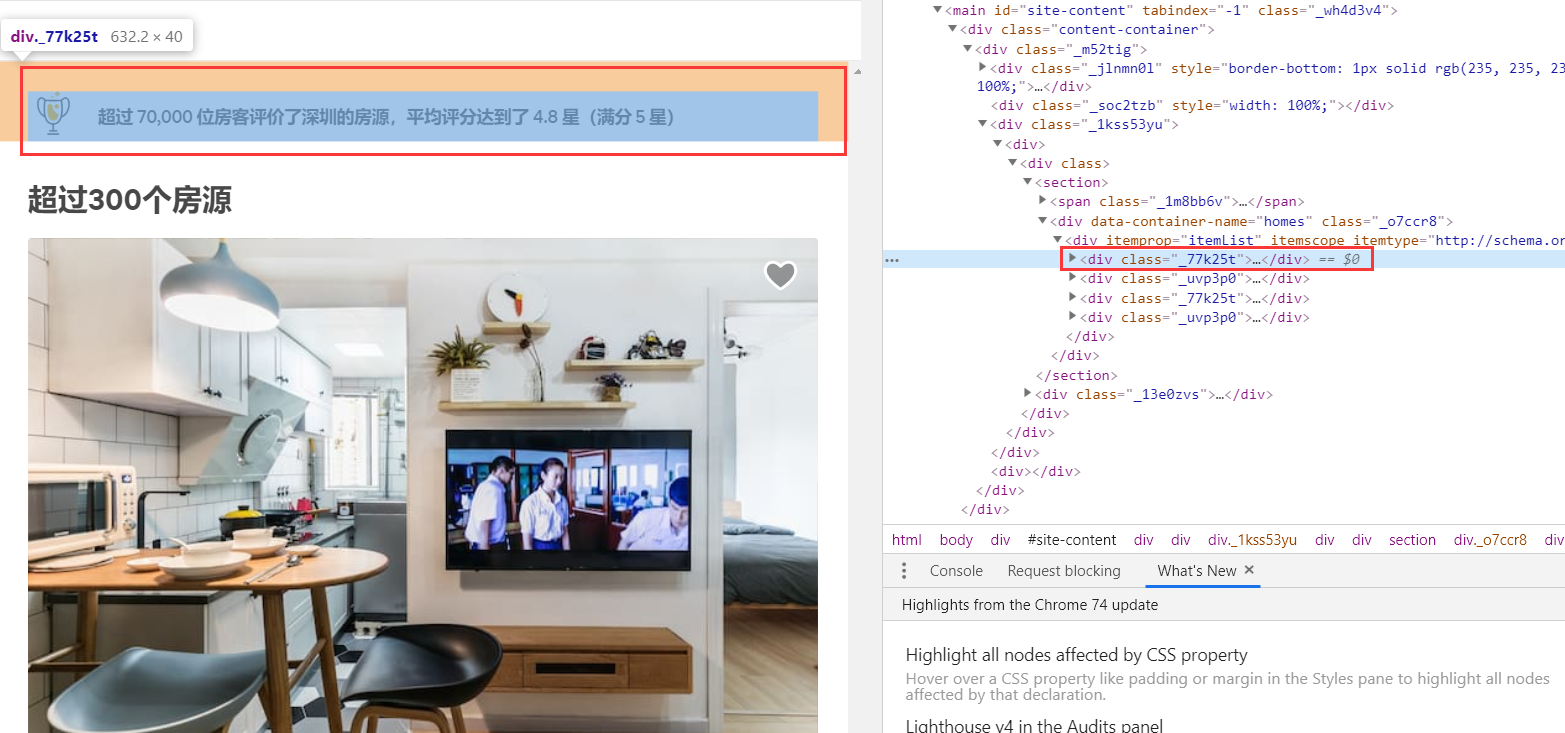
第二部分:
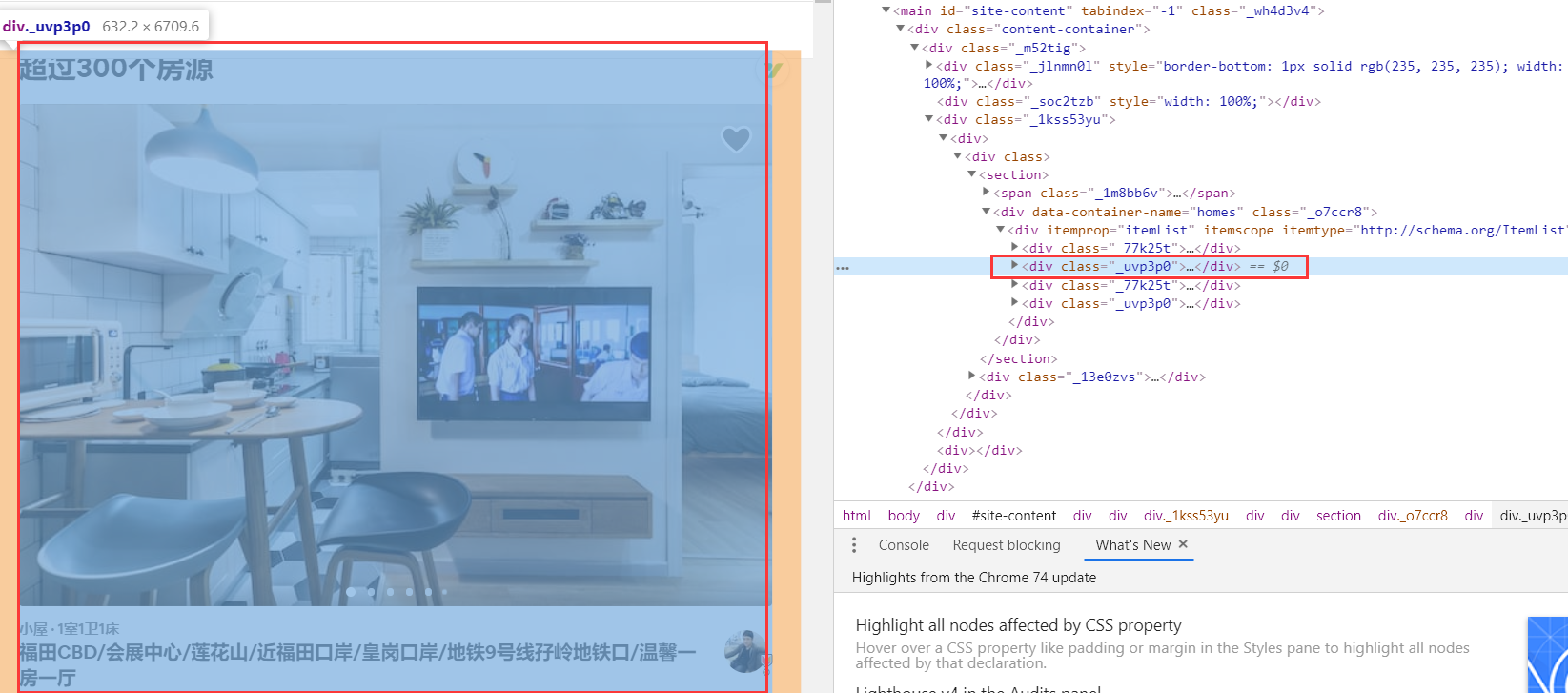
第三部分:
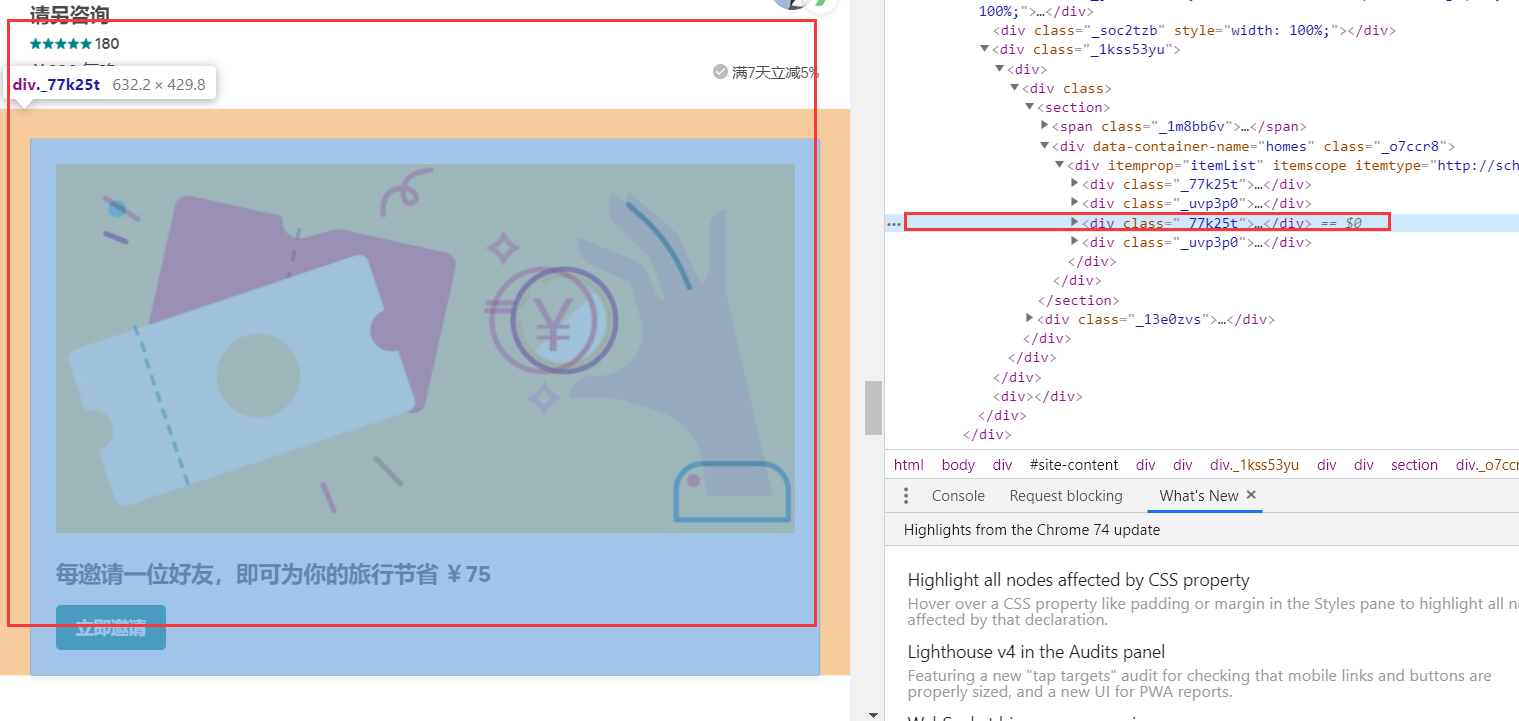
第四部分:
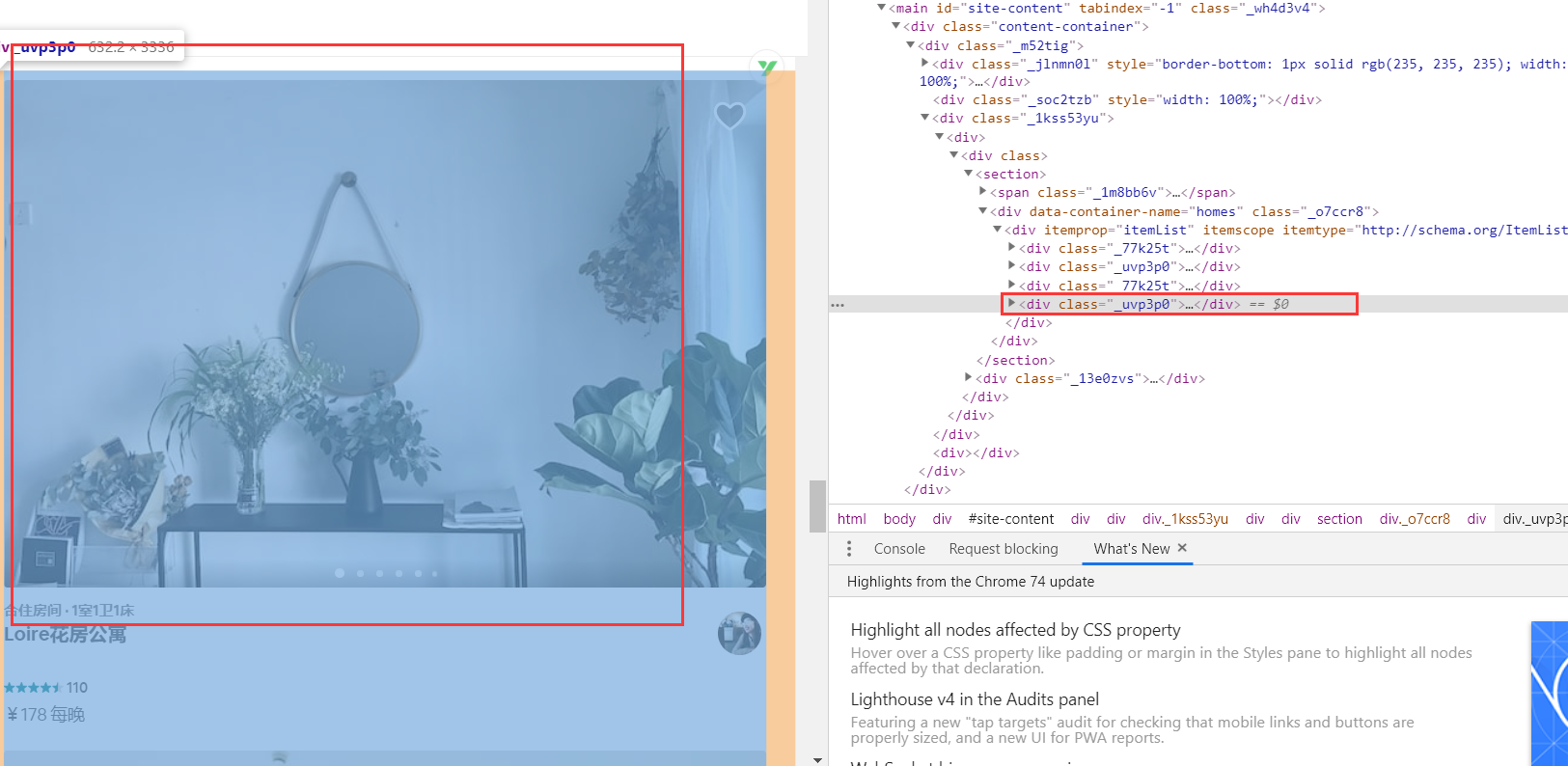
主体部分就是这四部分了,但是我们发现,包含房源信息的主要在第二部分和第四部分,也就是<div class="_uvp3p0">这里面,并且每一个房源信息都在<div class="_14csrlku">,但是第一页第二部分有12个房源信息,第四部分有6个房源信息,被分开了。这是第一页的情况。
我们在点击第二页,发现房源信息集中在<div class="_uvp3p0">,并且在第二页只有一块主题用于放置房源信息,并且第二页房源信息为18个,都在<div class="_14csrlku">。
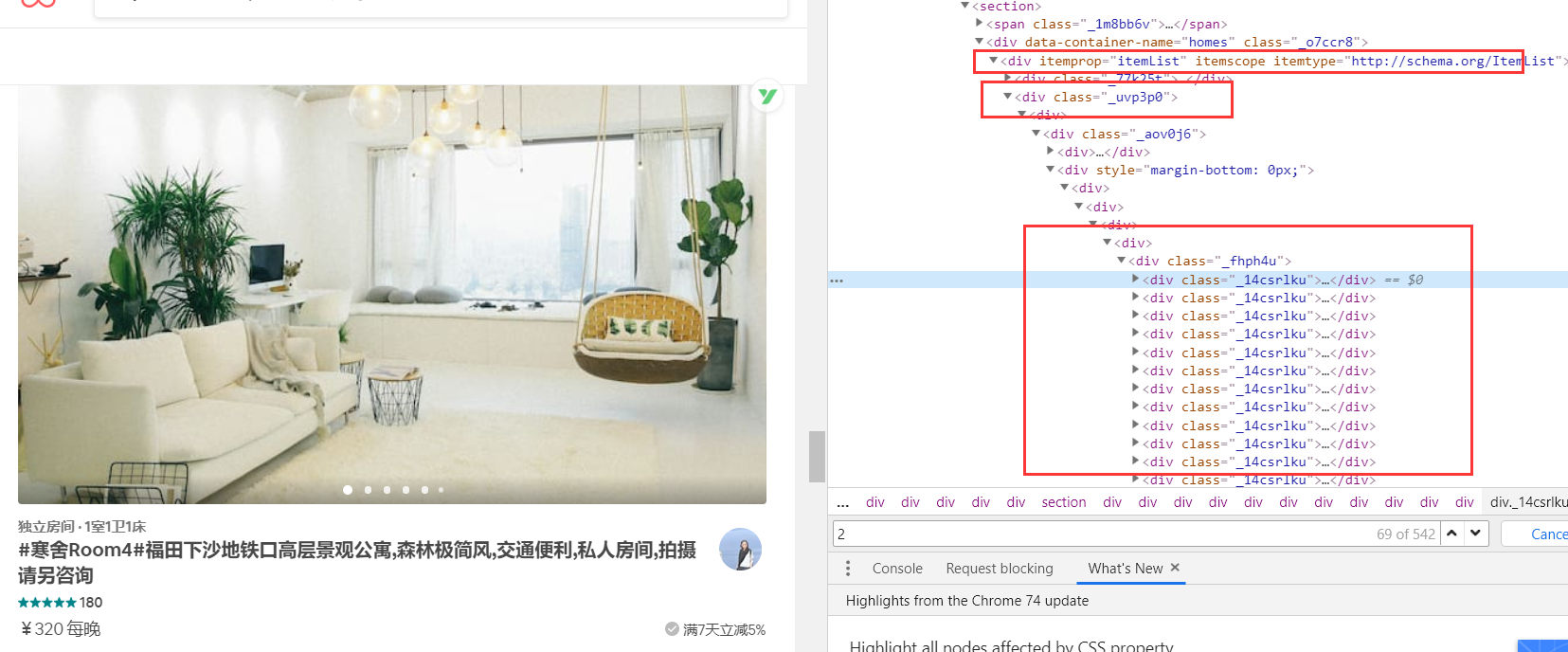
好了,我们现在可以初步断定,我们需要的所有信息都包含在这个块中,接下来我们在这个模块中搜寻信息。
#_*_ coding=UTF-8 _*_
import requests
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"')
driver = webdriver.Chrome(chrome_options = options)
#第1页第二部分:
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div:nth-child(2) > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(3)
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div:nth-child(2) > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(1)
#第1页第四部分
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div:nth-child(4) > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(6)
#第一页和其它页的selector不通用,除第一页外剩余页均通用
#第4页第17条信息
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(17)
#第5页第15条信息
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(15)
#site-content > div > div > div._1kss53yu > div > div > section > div > div > div > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child(17)
#第一页第二部分
driver.get("https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain")
for num in range(1,13):
info=driver.find_element_by_css_selector('#site-content > div > div > div._1kss53yu > div > div > section > div > div > div:nth-child(2) > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child('+str(num)+')')#可通过浏览器检查元素,copy->copyselector获取。
sty=info.find_element_by_css_selector('span._fk7kh10')#样式
#st=info.find_element_by_class_name('_fk7kh10')
name=info.find_element_by_css_selector('div._dadnbjj')#name
comment=info.find_element_by_css_selector('span._69pvqtq')#评论
price=info.find_element_by_css_selector('span._j1kt73')#价格
print("样式:"+sty.text)
print("名字:"+name.text)
print("评论数:"+comment.text)
print("价格:"+price.text)
#print(info.text)
#第一页第四部分
#driver.get("https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain")
for num in range(1,7):
info=driver.find_element_by_css_selector('#site-content > div > div > div._1kss53yu > div > div > section > div > div > div:nth-child(4) > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child('+str(num)+')')#可通过浏览器检查元素,copy->copyselector获取。
sty=info.find_element_by_css_selector('span._fk7kh10')#样式
#st=info.find_element_by_class_name('_fk7kh10')
name=info.find_element_by_css_selector('div._dadnbjj')#name
comment=info.find_element_by_css_selector('span._69pvqtq')#评论
price=info.find_element_by_css_selector('span._j1kt73')#价格
print("样式:"+sty.text)
print("名字:"+name.text)
print("评论数:"+comment.text)
print("价格:"+price.text)
#其它页面
#https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain§ion_offset=6&items_offset=18#第二页
#https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain§ion_offset=6&items_offset=36#第三页
#https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain§ion_offset=6&items_offset=54#第四页
for i in range(2,18):
url="https://www.airbnb.cn/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&place_id=ChIJkVLh0Aj0AzQRyYCStw1V7v0&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=vaSZFain§ion_offset=6&items_offset="+str(18*(i-1))
driver.get(url)
for num in range(1,19):
info=driver.find_element_by_css_selector('#site-content > div > div > div._1kss53yu > div > div > section > div > div > div > div > div > div:nth-child(2) > div > div > div > div > div > div:nth-child('+str(num)+')')#可通过浏览器检查元素,copy->copyselector获取。
sty=info.find_element_by_css_selector('span._fk7kh10')#样式
#st=info.find_element_by_class_name('_fk7kh10')
name=info.find_element_by_css_selector('div._dadnbjj')#name
comment=info.find_element_by_css_selector('span._69pvqtq')#评论
price=info.find_element_by_css_selector('span._j1kt73')#价格
print("样式:"+sty.text)
print("名字:"+name.text)
print("评论数:"+comment.text)
print("价格:"+price.text)
driver.quit()
代码没有做任何优化,注释部分可以方便我们理解。 采集结果如下:

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。