

虚函数与虚继承寻踪
封装、继承、多态是面向对象语言的三大特性,熟悉C++的人对此应该不会有太多异议。C语言提供的struct,顶多算得上对数据的简单封装,而C++的引入把struct“升级”为class,使得面向对象的概念更加强大。继承机制解决了对象复用的问题,然而多重继承又会产生成员冲突的问题,虚继承在我看来更像是一种“不得已”的解决方案。多态让对象具有了运行时特性,并且它是软件设计复用的本质,虚函数的出现为多态性质提供了实现手段。
如果说C语言的struct相当于对数据成员简单的排列(可能有对齐问题),那么C++的class让对象的数据的封装变得更加复杂。所有的这些问题来源于C++的一个关键字——virtual!virtual在C++中最大的功能就是声明虚函数和虚基类,有了这种机制,C++对象的机制究竟发生了怎样的变化,让我们一起探寻之。
为了查看对象的结构模型,我们需要在编译器配置时做一些初始化。在VS2010中,在项目——属性——配置属性——C/C++——命令行——其他选项中添加选项“/d1reportAllClassLayout”。再次编译时候,编译器会输出所有定义类的对象模型。由于输出的信息过多,我们可以使用“Ctrl+F”查找命令,找到对象模型的输出。
一、基本对象模型
首先,我们定义一个简单的类,它含有一个数据成员和一个虚函数。
{
int var;
public:
virtual void fun()
{}
};
编译输出的MyClass对象结构如下:
1> +---
1> 0 | {vfptr}
1> 4 | var
1> +---
1>
1> MyClass::$vftable@:
1> | &MyClass_Meta
1> | 0
1> 0 | &MyClass::fun
1>
1> MyClass::fun this adjustor: 0
从这段信息中我们看出,MyClass对象大小是8个字节。前四个字节存储的是虚函数表的指针vfptr,后四个字节存储对象成员var的值。虚函数表的大小为4字节,就一条函数地址,即虚函数fun的地址,它在虚函数表vftable的偏移是0。因此,MyClass对象模型的结果如图1所示。

图1 MyClass对象模型
MyClass的虚函数表虽然只有一条函数记录,但是它的结尾处是由4字节的0作为结束标记的。
adjust表示虚函数机制执行时,this指针的调整量,假如fun被多态调用的话,那么它的形式如下:
*(this+0)[0]()
*(this指针+调整量)[虚函数在vftable内的偏移]()
二、单重继承对象模型
我们定义一个继承于MyClass类的子类MyClassA,它重写了fun函数,并且提供了一个新的虚函数funA。
它的对象模型为:
可以看出,MyClassA将基类MyClass完全包含在自己内部,包括vfptr和var。并且虚函数表内的记录多了一条——MyClassA自己定义的虚函数funA。它的对象模型如图2所示。

图2 MyClassA对象模型
我们可以得出结论:在单继承形式下,子类的完全获得父类的虚函数表和数据。子类如果重写了父类的虚函数(如fun),就会把虚函数表原本fun对应的记录(内容MyClass::fun)覆盖为新的函数地址(内容MyClassA::fun),否则继续保持原本的函数地址记录。如果子类定义了新的虚函数,虚函数表内会追加一条记录,记录该函数的地址(如MyClassA::funA)。
使用这种方式,就可以实现多态的特性。假设我们使用如下语句:
pc->fun();
编译器在处理第二条语句时,发现这是一个多态的调用,那么就会按照上边我们对虚函数的多态访问机制调用函数fun。
*(pc+0)[0]()
因为虚函数表内的函数地址已经被子类重写的fun函数地址覆盖了,因此该处调用的函数正是MyClassA::fun,而不是基类的MyClass::fun。
如果使用MyClassA对象直接访问fun,则不会出发多态机制,因为这个函数调用在编译时期是可以确定的,编译器只需要直接调用MyClassA::fun即可。
三、多重继承对象模型
和前边MyClassA类似,我们也定义一个类MyClassB。
{
int varB;
public:
virtual void fun()
{}
virtual void funB()
{}
};
它的对象模型和MyClassA完全类似,这里就不再赘述了。
为了实现多重继承,我们再定义一个类MyClassC。
{
int varC;
public:
virtual void funB()
{}
virtual void funC()
{}
};
为了简化,我们让MyClassC只重写父类MyClassB的虚函数funB,它的对象模型如下:
1> +---
1> | +--- (base class MyClassA)
1> | | +--- (base class MyClass)
1> 0 | | | {vfptr}
1> 4 | | | var
1> | | +---
1> 8 | | vara
1> | +---
1> | +--- (base class MyClassB)
1> | | +--- (base class MyClass)
1> 12 | | | {vfptr}
1> 16 | | | var
1> | | +---
1> 20 | | varB
1> | +---
1> 24 | varC
1> +---
1>
1> MyClassC::$vftable@MyClassA@:
1> | &MyClassC_Meta
1> | 0
1> 0 | &MyClassA::fun
1> 1 | &MyClassA::funA
1> 2 | &MyClassC::funC
1>
1> MyClassC::$vftable@MyClassB@:
1> | -12
1> 0 | &MyClassB::fun
1> 1 | &MyClassC::funB
1>
1> MyClassC::funB this adjustor: 12
1> MyClassC::funC this adjustor: 0
和单重继承类似,多重继承时MyClassC会把所有的父类全部按序包含在自身内部。而且每一个父类都对应一个单独的虚函数表。MyClassC的对象模型如图3所示。
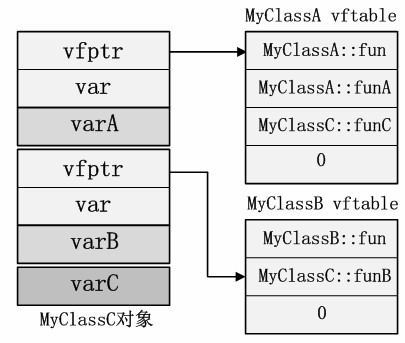
图3 MyClassC对象模型
多重继承下,子类不再具有自身的虚函数表,它的虚函数表与第一个父类的虚函数表合并了。同样的,如果子类重写了任意父类的虚函数,都会覆盖对应的函数地址记录。如果MyClassC重写了fun函数(两个父类都有该函数),那么两个虚函数表的记录都需要被覆盖!在这里我们发现MyClassC::funB的函数对应的adjust值是12,按照我们前边的规则,可以发现该函数的多态调用形式为:
*(this+12)[1]()
此处的调整量12正好是MyClassB的vfptr在MyClassC对象内的偏移量。
四、虚拟继承对象模型
虚拟继承是为了解决多重继承下公共基类的多份拷贝问题。比如上边的例子中MyClassC的对象内包含MyClassA和MyClassB子对象,但是MyClassA和MyClassB内含有共同的基类MyClass。为了消除MyClass子对象的多份存在,我们需要让MyClassA和MyClassB都虚拟继承于MyClass,然后再让MyClassC多重继承于这两个父类。相对于上边的例子,类内的设计不做任何改动,先修改MyClassA和MyClassB的继承方式:
class MyClassB:virtual public MyClass
class MyClassC:public MyClassA,public MyClassB
由于虚继承的本身语义,MyClassC内必须重写fun函数,因此我们需要再重写fun函数。这种情况下,MyClassC的对象模型如下:
1> +---
1> | +--- (base class MyClassA)
1> 0 | | {vfptr}
1> 4 | | {vbptr}
1> 8 | | vara
1> | +---
1> | +--- (base class MyClassB)
1> 12 | | {vfptr}
1> 16 | | {vbptr}
1> 20 | | varB
1> | +---
1> 24 | varC
1> +---
1> +--- (virtual base MyClass)
1> 28 | {vfptr}
1> 32 | var
1> +---
1>
1> MyClassC::$vftable@MyClassA@:
1> | &MyClassC_Meta
1> | 0
1> 0 | &MyClassA::funA
1> 1 | &MyClassC::funC
1>
1> MyClassC::$vftable@MyClassB@:
1> | -12
1> 0 | &MyClassC::funB
1>
1> MyClassC::$vbtable@MyClassA@:
1> 0 | -4
1> 1 | 24 (MyClassCd(MyClassA+4)MyClass)
1>
1> MyClassC::$vbtable@MyClassB@:
1> 0 | -4
1> 1 | 12 (MyClassCd(MyClassB+4)MyClass)
1>
1> MyClassC::$vftable@MyClass@:
1> | -28
1> 0 | &MyClassC::fun
1>
1> MyClassC::fun this adjustor: 28
1> MyClassC::funB this adjustor: 12
1> MyClassC::funC this adjustor: 0
1>
1> vbi: class offset o.vbptr o.vbte fVtordisp
1> MyClass 28 4 4 0
虚继承的引入把对象的模型变得十分复杂,除了每个基类(MyClassA和MyClassB)和公共基类(MyClass)的虚函数表指针需要记录外,每个虚拟继承了MyClass的父类还需要记录一个虚基类表vbtable的指针vbptr。MyClassC的对象模型如图4所示。
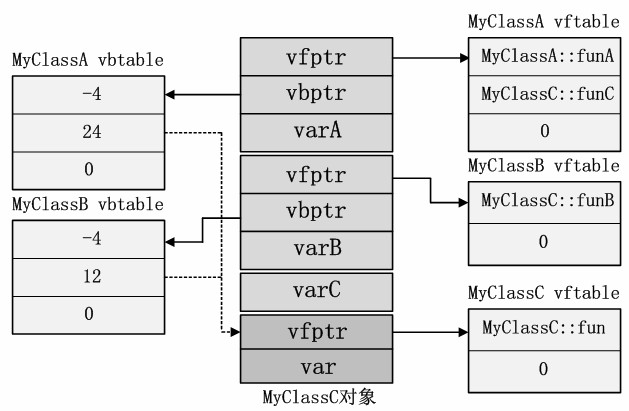
图4 MyClassC对象模型
虚基类表每项记录了被继承的虚基类子对象相对于虚基类表指针的偏移量。比如MyClassA的虚基类表第二项记录值为24,正是MyClass::vfptr相对于MyClassA::vbptr的偏移量,同理MyClassB的虚基类表第二项记录值12也正是MyClass::vfptr相对于MyClassA::vbptr的偏移量。
和虚函数表不同的是,虚基类表的第一项记录着当前子对象相对与虚基类表指针的偏移。MyClassA和MyClassB子对象内的虚表指针都是存储在相对于自身的4字节偏移处,因此该值是-4。假定MyClassA和MyClassC或者MyClassB内没有定义新的虚函数,即不会产生虚函数表,那么虚基类表第一项字段的值应该是0。
通过以上的对象组织形式,编译器解决了公共虚基类的多份拷贝的问题。通过每个父类的虚基类表指针,都能找到被公共使用的虚基类的子对象的位置,并依次访问虚基类子对象的数据。至于虚基类定义的虚函数,它和其他的虚函数的访问形式相同,本例中,如果使用虚基类指针MyClass*pc访问MyClassC对象的fun,将会被转化为如下形式:
*(pc+28)[0]()
通过以上的描述,我们基本认清了C++的对象模型。尤其是在多重、虚拟继承下的复杂结构。通过这些真实的例子,使得我们认清C++内class的本质,以此指导我们更好的书写我们的程序。本文从对象结构的角度结合图例为大家阐述对象的基本模型,和一般描述C++虚拟机制的文章有所不同。作者只希望借助于图表能把C++对象以更好理解的形式为大家展现出来,希望本文对你有所帮助。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
