

对象的传值与返回
说起函数,就不免要谈谈函数的参数和返回值。一般的,我们习惯把函数看作一个处理的封装(比如黑箱),而参数和返回值一般对应着处理过程的输入和输出。这种情况下,参数和返回值都是值类型的,也就是说,函数和它的调用者的信息交流方式是用过数据的拷贝来完成,即我们习惯上称呼的“值传递”。但是自从引入了“引用”的概念后,函数的传统模型就不再那么“和谐”了。引用的传递可以允许函数和调用者共享数据对象,它们之间的信息交流不再使用信息拷贝的方式,而是使用更有效率的信息共享的方式,引用导致函数的参数并有输入和输出的双重功能。然而,事物总有两面性,信息共享带来方便的同时也带来了一定的不安全性。我们这里并不讨论函数的使用和设计,我们关注与函数参数和返回值的传递方式。
对于内置数据类型的参数和返回值,函数实际参数的传递一般是通过压栈完成,函数执行时会从栈内取出参数的值进行计算。在32处理器上,push指令一次只能压入4个字节的数据,那么对于long long就需要两次压栈指令了,而double类型参数就需要sub esp,8结合mov指令完成参数进栈的操作。函数带有返回值时,若返回值不大于4字节,则会把返回值存储在eax寄存器中,而long long类型返回值回保存在edx:eax寄存器中,double类型的数据会被协处理器栈保存。
相对于内置类型的参数传递和返回值,对象的传值和返回可能更复杂一点。当然,如果使用对象的引用或者指针作为参数传递和返回值的方式,这里和上述的内置类型并无多大区别,因为指针总是4个字节。如果不使用引用和指针,单纯传递纯粹的对象时,编译器会如何处理呢?
为此,我们定义一个简单的类A,为了防止编译器对我们的代码优化处理(参考我的前一篇博文),我们自己定义构造函数、复制构造函数和赋值运算符重载函数。
{
int x;
int y;
int z;
public:
A(){}
A(const A&a)
{
x=a.x;
y=a.y;
z=a.z;
}
const A&operator=(const A&a)
{
x=a.x;
y=a.y;
z=a.z;
}
};
{
return x;
}
A a;
a=fun(a);
试想一下,如果A不是自定义类型,而是int类型的话,这段测试代码会有怎样的效果。
push eax;//a值进栈
call fun;//调用fun
add esp,4;//恢复栈指针
mov [a],eax;//返回值写入a
;//而fun内部无非也是把参数x的值写入eax,然后返回而已。
mov eax,[a]
ret
事实是这样的吗?我们看一下VS2010的反汇编。
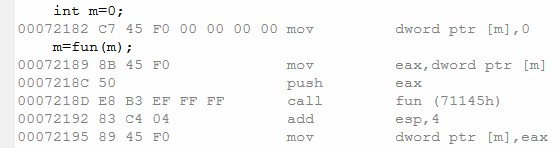
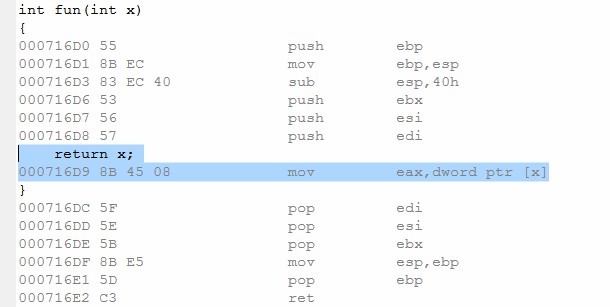
和我们的预期完全一致!
现在,我们回到对象的问题上来。由于对象是值传递方式,因此,对象传递之前需要进行一次对象拷贝(从原对象到实参)。函数调用结束后还需要将返回值对象进行一次拷贝。我们看看VS2010的处理方式。
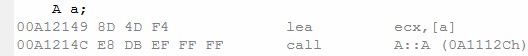
对象a定义是需要调用它的构造函数A::A(

对象A包含三个整形数据成员,因此它的大小是12(0x
mov ecx,esp记录了被拷贝的参数对象的地址(this指针),push eax压入的是a的地址,也就是拷贝构造函数调用时参数对象的地址(引用)。拷贝构造函数(A::A(

push ecx压入了内存地址ebp-58h,这个地址既不是a的地址,也不是拷贝出参数对象的地址,而是要保存返回对象的地址!调用fun之前将该地址压栈,就是为了保存fun处理结束后的返回值对象。fun调用结束后将esp指针恢复了16字节,正好是参数对象的大小(12字节)加上返回值对象的地址(4字节)之和!要获得fun的返回值,直接访问eax即可,因为它保存着返回值对象的地址(ebp-58h)!

最后一步是对象的赋值,这里需要调用对象的赋值运算符重载函数。而参数正是刚才fun调用结束后eax的值,因为它存储了返回值对象的地址。ecx记录this指针,正是被赋值对象的地址(a的地址)。赋值运算符重载函数调用结束后,完成返回值对象的赋值操作。
按照编译器产生的fun函数的语义,我们使用高级语言可以将它的意思描述如下。
我们看一下fun的汇编代码。

参数对象的地址被x记录了下来,ebp+8记录的正是函数第一个参数的内容,即返回值对象的地址!在拷贝构造函数调用之前,ecx保存的this指针正是返回值对象的,进栈的参数是x的地址,和我们预期的一样!
因此,我们可以针对对象的传值和返回得出如下结论:
1. 对象参数传递之前需要进行一次对象拷贝,将原对象的内容完整的拷贝到参数对象内部,函数执行时访问的是参数对象,而不是原对象。
2. 对象返回时,也需要将函数处理的结果进行一次对象拷贝,不过被拷贝的返回值对象内存已经在函数调用之前已经开辟出来了,函数只需要记录它的地址即可,然后调用拷贝构造函数初始化它。
3. 函数调用结束后,eax保存了返回值对象的地址,供调用者使用。
通过本文的描述,相信读者对对象作为函数参数和返回值时,编译器的内部处理机制有个更清晰的了解。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
