

1、安装virtualenv
virtualenv是一个常用的用来创建python环境的工具。小喵用这个有两个原因,一是为了不污染本机的环境,二是在本机直接安装库的时候出了一个权限的问题。
virtualenv的安装十分简单,使用pip工具就可以安装。
1pip install virtualenv
待程序执行结束,你就会开心的发现自己已经有了virtualenv这个工具了。
2、创建python环境
virtualenv的使用非常的方便。
建立新的运行环境:virtualenv <env-name>
进入相应的独立环境:source <env-path>/bin/activate
执行完第一个指令后,就会创建成功一个python环境,执行第二个指令后,就会发现命令行的起始位置有变化。这时候python、pip等工具就变成使用这个新环境的了,当然也可以使用which python来查看。
3、安装selenium
进入新环境后,pip安装的依赖库都会在新环境中安装,不会影响主机自身的python。使用pip 安装selenium:
1pip install selenium
至此,我们的基本环境就搭建完了。
4、安装PhantomJs
这个只在从官网上下载就可以:http://phantomjs.org/download.html
首页
为了减小图片的大小,小喵把窗口做了缩放。首页大致是这个样子。
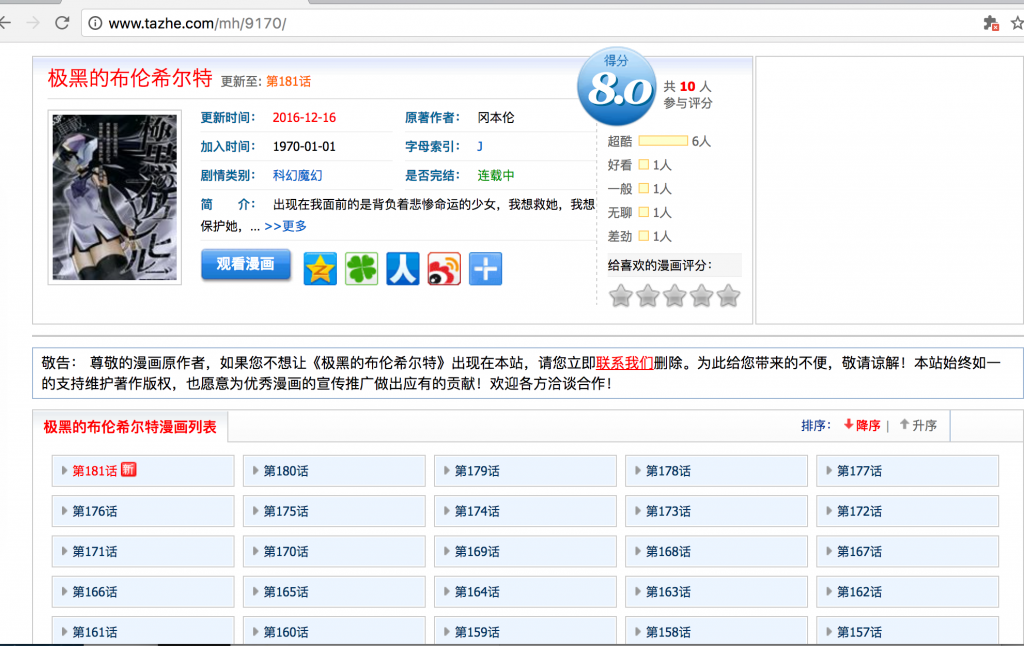
图1 漫画首页
各类信息十分的明了。我们关注的就是下面的漫画列表。通过Chrome强大的审查元素的功能,我们立刻就能定位到章节的位置。(对着感兴趣的位置->右键->审查 就能找到)
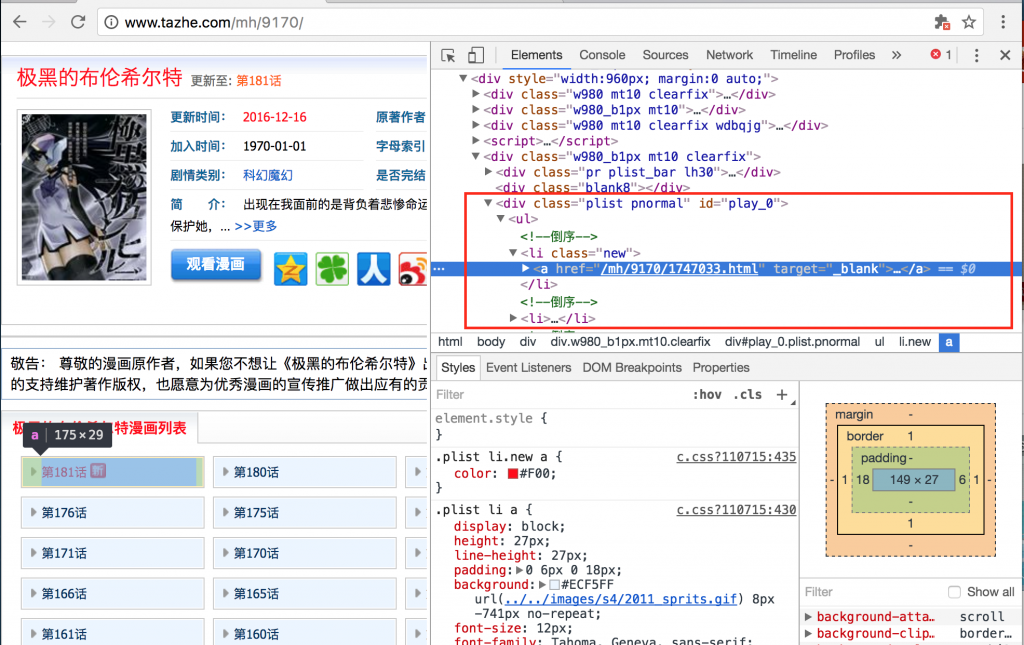
图2 章节的节点
可以看到,章节所在的区域的id是play_0,学过前端的童鞋都应该知道,一个页面中id通常唯一标示一个节点。因此如果我们能够获取这个页面的话,查找id为play_0的节点就能一下子缩小搜索范围。
而每个章节的信息都是一个a标签,标签的href是对应章节的具体网址,标签的文本部分是章节名。这样相对关系就得出了:div#play_0 > ul > li > a。
首页的分析就到此结束。
章节页面
我们把鼠标放在图片这个区域->右键->审查。
咦,我们的右键怎么按不了?
那么我们如何绕过这个陷阱呢?
很简单,我们不用右键即可。打开浏览器的开发者工具选项,找到elements这个选项。可以看到一个复杂的结构(其实和上面审查元素之后的结果一样)。之后不断的选中标签,当标签被选中时,左侧页面中对应的位置会有蓝色。多试几次,最终就能找到对应的位置。
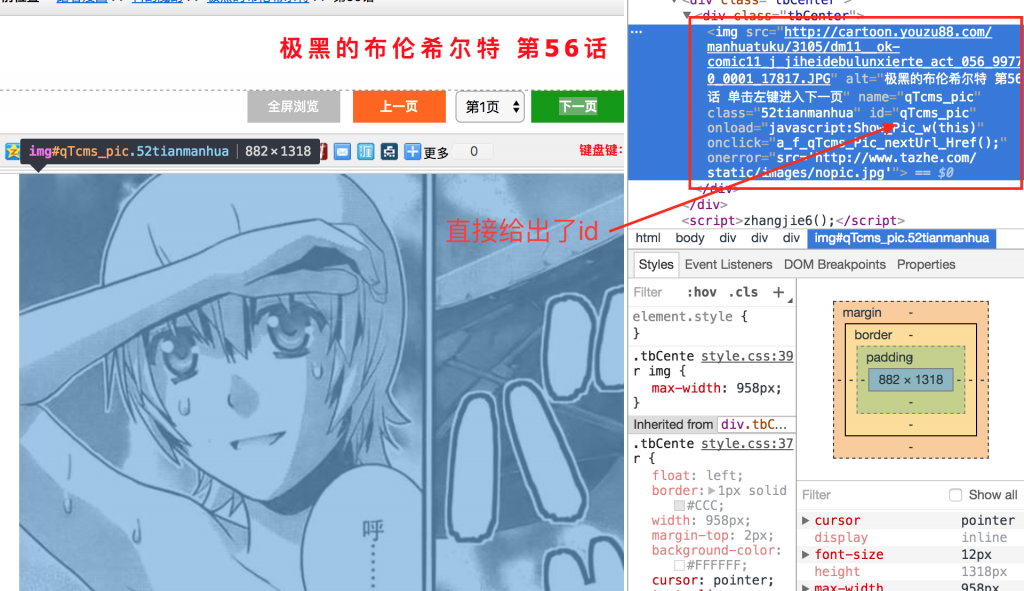
图3 漫画图片
这是一个img标签,对应的id是qTcms_pic。这样找到这个id,就能找到这个img标签,根据src就能找到图片的具体URI地址。
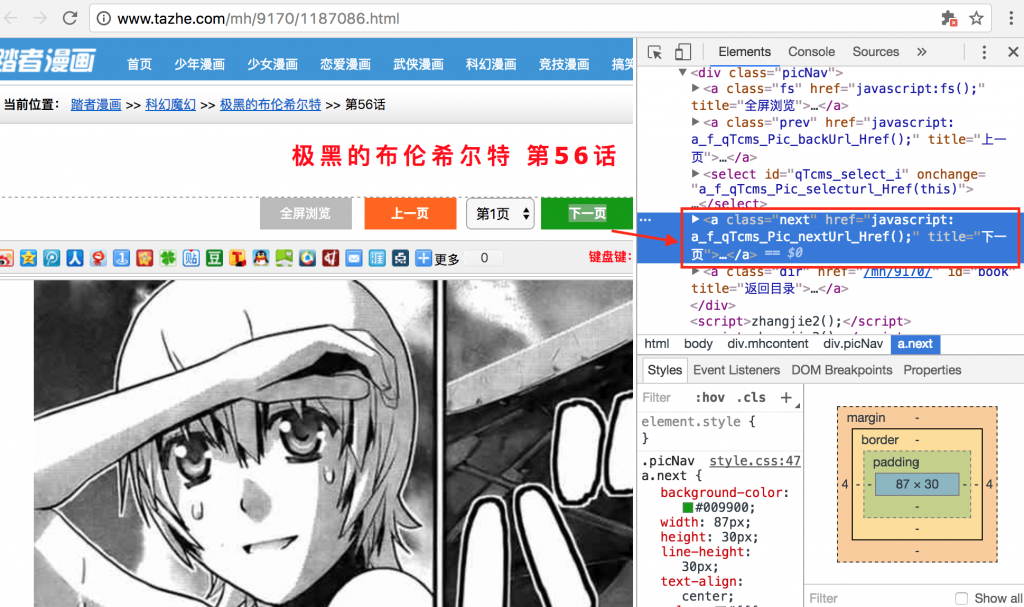
接下来是找到下一张图片的地址。这时候需要查看下一页这个按钮的内容。用相同的方法,很容易定位成功。
代码实现
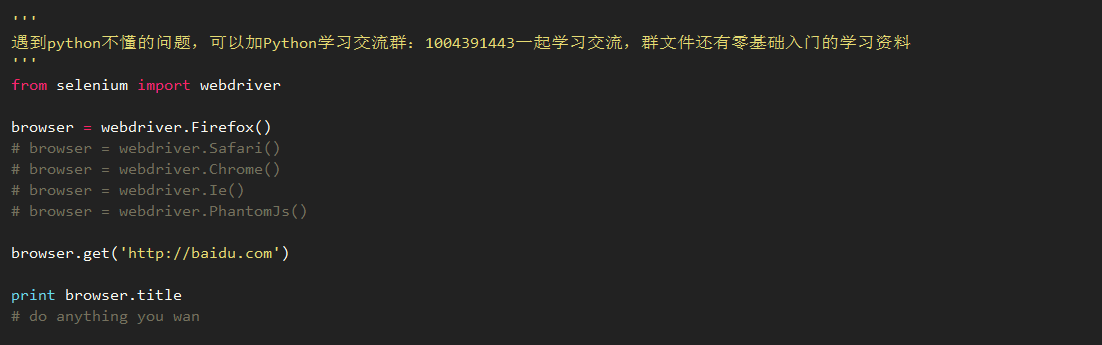
上面是一个简单的例子,第一步import依赖的库。
第二步,获得一个浏览器实例。selenium支持多种浏览器。使用firefox之外的浏览器都需要下载驱动(selenium本身自带了firefox的驱动)。驱动下载地址:https://pypi.python.org/pypi/selenium。驱动下载完之后将它的路径加入到PATH里,确保驱动程序能够被访问到。或者显式的把驱动程序的地址当参数传入。像下面一样调用:
1browser = webdriver.PhantomJs('path/to/phantomjs')
第三步,用get的方式打开网页。
最后,通过browser对象来解析和处理页面。
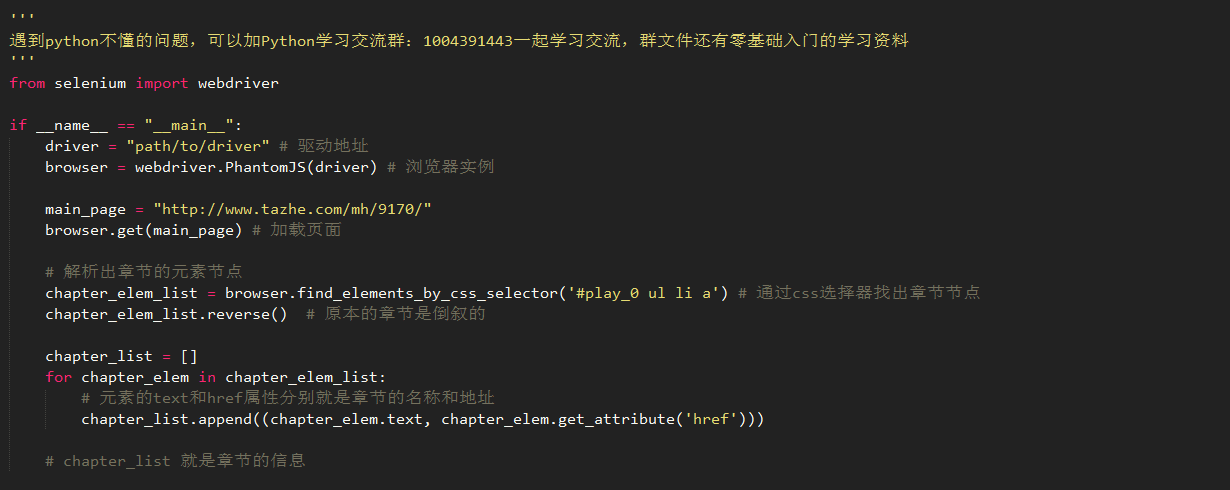
2,获取章节的链接信息
在上面的解析页面的时候,我们知道了章节信息的位置:div#play_0 > ul > li > a。这样就可以解析出章节信息。browser支持一大堆的选择器。大大简化我们查找节点的工作。
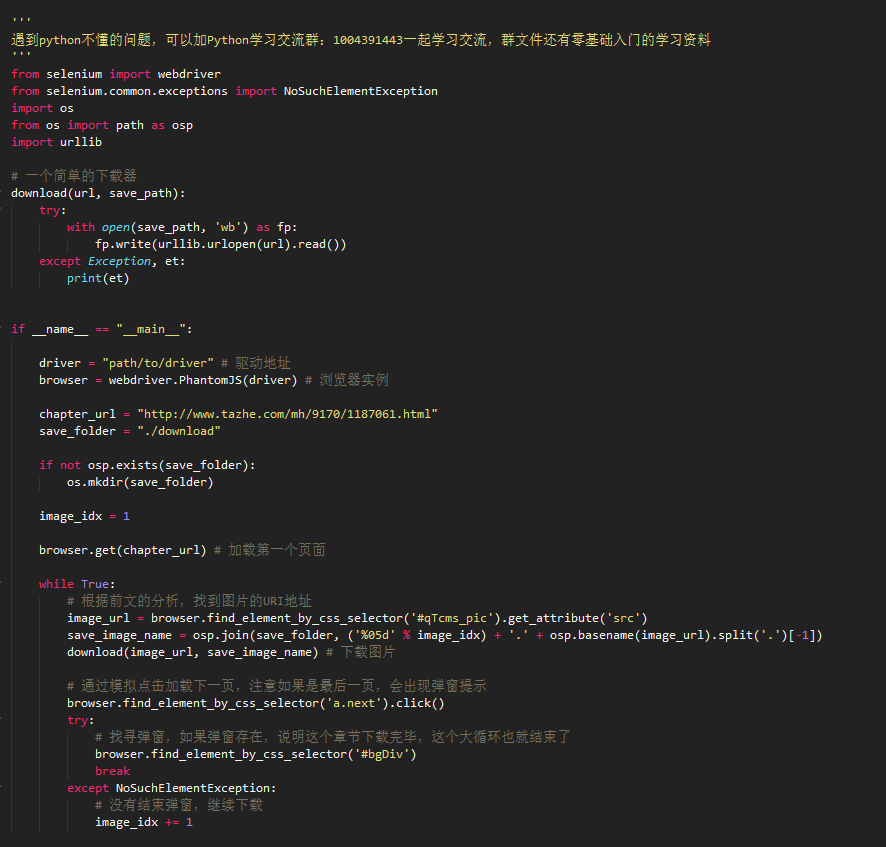
3,给定一个章节的地址,章节中的图片
这一步涉及到节点的获取、模拟鼠标的点击以及资源的下载。selenium的点击实现特别的人性化。只需要获取节点然后调用click()方法就搞定。资源的下载网上有许多教程,主要有两个方法,通过模拟右键另存为,和获取url用其他工具下载。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
